网站建设 盘网互联百度导航是哪个国家的
pytorch的C++ extension写法
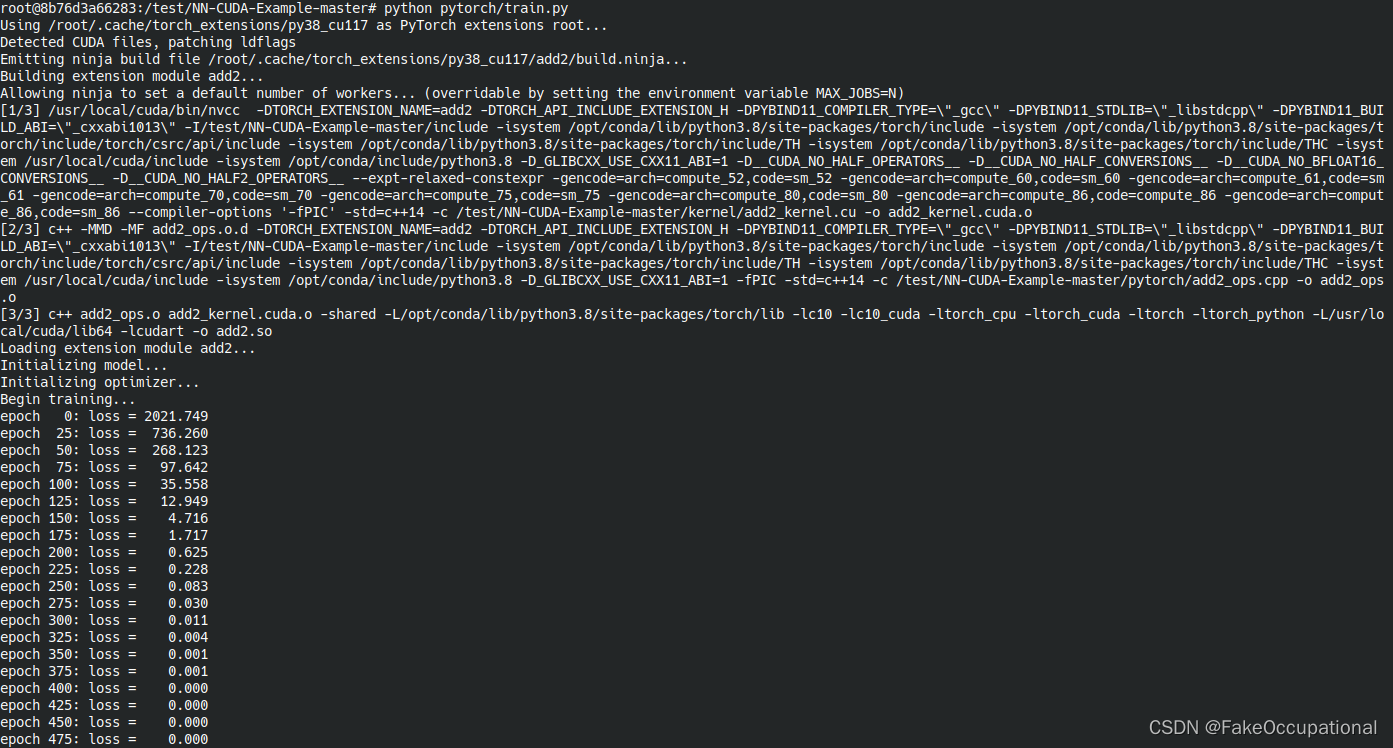
这部分主要介绍如何在pytorch中添加自定义的算子,需要以下cuda基础。就总体的逻辑来说正向传播需要输入数据,反向传播需要输入数据和上一层的梯度,然后分别实现这两个kernel,将这两个kernerl绑定到pytorch即可。
add
- 但实际上来说,这可能不是一个很好的教程,因为加法中没有对输入的grad_out进行继续的操作(不用写cuda的操作)。所以实际上只需要正向传播的launch_add2函数。更重要的是作者大佬写了博客介绍。
// https://github.com/godweiyang/NN-CUDA-Example/blob/master/kernel/add2_kernel.cu__global__ void add2_kernel(float* c,const float* a,const float* b,int n) {for (int i = blockIdx.x * blockDim.x + threadIdx.x; \i < n; i += gridDim.x * blockDim.x) {c[i] = a[i] + b[i];}
}void launch_add2(float* c,const float* a,const float* b,int n) {// 创建 [(n + 1023) / 1024 ,1 ,1]的三维向量数据dim3 grid((n + 1023) / 1024);//dim3 为CUDA中三维向量结构体// 创建 [1024 ,1 ,1]的三维向量数据dim3 block(1024);// 函数add2_kernel实现两个n维向量相加// 共有(n + 1023) / 1024*1*1个block , 每个block有1024*1*1个线程add2_kernel<<<grid, block>>>(c, a, b, n);
}
binary activation function
- 正向计算为:
x > 1 ? 1 : -1;// 也可以使用sign() 函数(求符号函数)实现
- 这篇文章作者没有自己写正向传播的算子,使用的是
at::sign
// https://github1s.com/jxgu1016/BinActivateFunc_PyTorch/blob/master/src/cuda/BinActivateFunc_cuda.cpp#L17-L22
at::Tensor BinActivateFunc_forward(at::Tensor input)
{CHECK_INPUT(input);return at::sign(input);
}
- 这篇文章用的Setuptools将写好的算子和pytorch链接起来,运行时需要安装一下(JIT运行时编译也很香,代码直接运行,就是cmakelist.txt需要各种环境配置很麻烦)。绑定部分见链接。以下是作者实现的反向传播的kernel:
// https://github.com/jxgu1016/BinActivateFunc_PyTorch/blob/master/src/cuda/BinActivateFunc_cuda_kernel.cu
#include <ATen/ATen.h>#include <cuda.h>
#include <cuda_runtime.h>#include <vector>// CUDA: grid stride looping
#define CUDA_KERNEL_LOOP(i, n) \for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < (n); i += blockDim.x * gridDim.x)namespace {
template <typename scalar_t>
__global__ void BinActivateFunc_cuda_backward_kernel(const int nthreads,const scalar_t* __restrict__ input_data,scalar_t* __restrict__ gradInput_data)
{CUDA_KERNEL_LOOP(n, nthreads) {if (*(input_data + n) > 1 || *(input_data + n) < -1) {*(gradInput_data + n) = 0;}}
}
} // namespaceint BinActivateFunc_cuda_backward(at::Tensor input,at::Tensor gradInput)
{const int nthreads = input.numel();const int CUDA_NUM_THREADS = 1024;const int nblocks = (nthreads + CUDA_NUM_THREADS - 1) / CUDA_NUM_THREADS;AT_DISPATCH_FLOATING_TYPES(input.type(), "BinActivateFunc_cuda_backward", ([&] {BinActivateFunc_cuda_backward_kernel<scalar_t><<<nblocks, CUDA_NUM_THREADS>>>(nthreads,input.data<scalar_t>(),gradInput.data<scalar_t>());}));return 1;
}
swish
// https://github1s.com/thomasbrandon/swish-torch/blob/HEAD/csrc/swish_kernel.cu
#include <torch/types.h>
#include <cuda_runtime.h>
#include "CUDAApplyUtils.cuh"// TORCH_CHECK replaces AT_CHECK in PyTorch 1,2, support 1.1 as well.
#ifndef TORCH_CHECK
#define TORCH_CHECK AT_CHECK
#endif#ifndef __CUDACC_EXTENDED_LAMBDA__
#error "please compile with --expt-extended-lambda"
#endifnamespace kernel {
#include "swish.h"using at::cuda::CUDA_tensor_apply2;
using at::cuda::CUDA_tensor_apply3;
using at::cuda::TensorArgType;template <typename scalar_t>
void
swish_forward(torch::Tensor &output,const torch::Tensor &input
) {CUDA_tensor_apply2<scalar_t,scalar_t>(output, input,[=] __host__ __device__ (scalar_t &out, const scalar_t &inp) {swish_fwd_func(out, inp);},TensorArgType::ReadWrite, TensorArgType::ReadOnly);
}template <typename scalar_t>
void
swish_backward(torch::Tensor &grad_inp,const torch::Tensor &input,const torch::Tensor &grad_out
) {CUDA_tensor_apply3<scalar_t,scalar_t,scalar_t>(grad_inp, input, grad_out,[=] __host__ __device__ (scalar_t &grad_inp, const scalar_t &inp, const scalar_t &grad_out) {swish_bwd_func(grad_inp, inp, grad_out);},TensorArgType::ReadWrite, TensorArgType::ReadOnly, TensorArgType::ReadOnly);
}} // namespace kernelvoid
swish_forward_cuda(torch::Tensor &output, const torch::Tensor &input
) {auto in_arg = torch::TensorArg(input, "input", 0),out_arg = torch::TensorArg(output, "output", 1);torch::checkAllDefined("swish_forward_cuda", {in_arg, out_arg});torch::checkAllSameGPU("swish_forward_cuda", {in_arg, out_arg});AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "swish_forward_cuda", [&] {kernel::swish_forward<scalar_t>(output, input);});
}void
swish_backward_cuda(torch::Tensor &grad_inp, const torch::Tensor &input, const torch::Tensor &grad_out
) {auto gi_arg = torch::TensorArg(grad_inp, "grad_inp", 0),in_arg = torch::TensorArg(input, "input", 1),go_arg = torch::TensorArg(grad_out, "grad_out", 2);torch::checkAllDefined("swish_backward_cuda", {gi_arg, in_arg, go_arg});torch::checkAllSameGPU("swish_backward_cuda", {gi_arg, in_arg, go_arg});AT_DISPATCH_FLOATING_TYPES_AND_HALF(grad_inp.scalar_type(), "swish_backward_cuda", [&] {kernel::swish_backward<scalar_t>(grad_inp, input, grad_out);});
}
cg
-
ScatWave是使用CUDA散射的Torch实现,主要使用lua语言https://github.com/edouardoyallon/scatwave
-
https://github.com/huangtinglin/PyTorch-extension-Convolution
-
This is a tutorial to explore how to customize operations in PyTorch.
-
https://pytorch.org/tutorials/advanced/cpp_extension.html
-
台湾博主 Pytorch+cpp/cuda extension 教學 tutorial 1 - English CC - B站搬运地址
-
pytorch的C++ extension写法
-
https://github.com/salinaaaaaa/NVIDIA-GPU-Tensor-Core-Accelerator-PyTorch-OpenCV
-
https://github.com/MariyaSha/Inference_withTorchTensorRT
-
项目介绍了简单的CUDA入门,涉及到CUDA执行模型、线程层次、CUDA内存模型、核函数的编写方式以及PyTorch使用CUDA扩展的两种方式。通过该项目可以基本入门基于PyTorch的CUDA扩展的开发方式。
RWKV CUDA
- 实例:手写 CUDA 算子,让 Pytorch 提速 20 倍(某特殊算子) https://zhuanlan.zhihu.com/p/476297195
- https://github.com/BlinkDL/RWKV-CUDA
- The CUDA version of the RWKV language model
数据加速
- 用于在 Pytorch 中更快地固定 CPU <-> GPU 传输的库
环境
- Docker images and github actions for building packages containing PyTorch C++/CUDA extensions.
一个构建系统,用于生成(相对)轻量级和便携式的 PyPI 轮子,其中包含 PyTorch C++/CUDA 扩展。使用Torch Extension Builder构建的轮子动态链接到用户PyTorch安装中包含的Torch和CUDA库。最终用户计算机上不需要安装 CUDA。
CG
- 又发现一个部署工具
研究人员很难将机器学习模型交付到生产环境。解决方案的一部分是Docker,但要让它工作非常复杂:Dockerfiles,预/后处理,Flask服务器,CUDA版本。通常情况下,研究人员必须与工程师坐下来部署该死的东西。安德烈亚斯和本创造了Cog。Andreas曾经在Spotify工作,在那里他构建了使用Docker构建和部署ML模型的工具。Ben 曾在 Docker 工作,在那里他创建了 Docker Compose。我们意识到,除了Spotify之外,其他公司也在使用Docker来构建和部署机器学习模型。Uber和其他公司也建立了类似的系统。因此,我们正在制作一个开源版本,以便其他人也可以这样做。如果您有兴趣使用它或想与我们合作,请与我们联系。我们在 Discord 上或给我们发电子邮件 team@replicate.com.