微信网站设计尺寸东莞网站提升排名
一、基于evaluation的prompt使用解析
基于大模型的应用评估与传统应用程序的评估不太一样,特别是基于GPT系列或者生成式语言模型,因为模型生成的内容与传统意义上所说的内容或者标签不太一样。
以下是借用了ChatGPT官方的evaluation指南提出的对结果的具体的评估步骤:
Compare the factual content of the submitted answer with the context. \
I gnore any differences in style, grammar, or punctuation.
Answer the following questions:
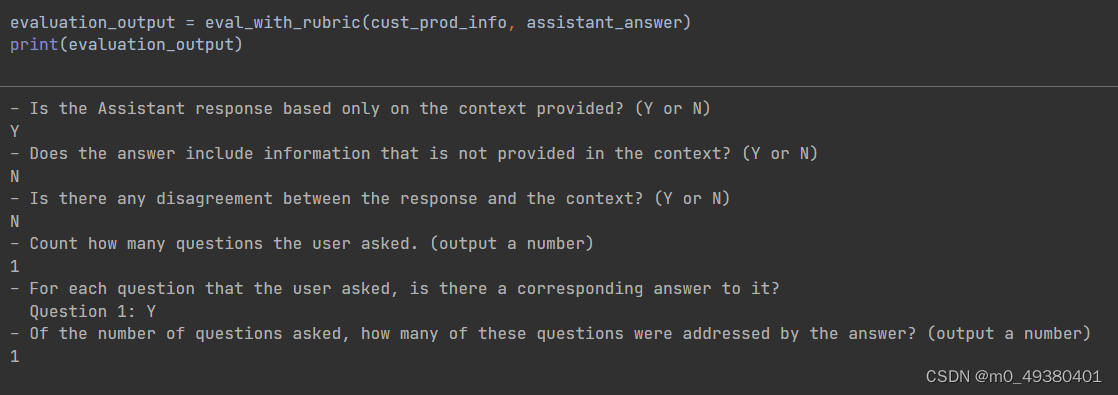
- Is the Assistant response based only on the context provided? (Y or N)
- Does the answer include information that is not provided in the context? (Y or N)
- Is there any disagreement between the response and the context? (Y or N)
- Count how many questions the user asked. (output a number)
- For each question that the user asked, is there a corresponding answer to it?
Question 1: (Y or N)
Question 2: (Y or N)
...
Question N: (Y or N)
- Of the number of questions asked, how many of these questions were addressed by the answer? (output a number)
所谓的factual content是指显性表达出来的(有明确文字说明的)内容,另外需要忽略掉写作风格,语法,标点符号等带来的差异,因为大多数情况下不同的用户表达同样的意思会有差异,这对于比较模型生成结果和你指定的正确答案来说很重要,否则会失去语言的灵活性。” Answer the following questions”部分说明了评估必须经过的步骤,另外也说明了不能简单地说“Y”或者“N”,而是需要给出一些中间的reasoning process或者说intermediate steps,这样的设计很具有技巧,考验你对业务的理解能力,包括对数据的理解能力以及对模型的理解能力等等。
在下面这个评估方法中,有用户的信息,上下文的信息以及对话机器人返回的信息,其中system_message如下:
You are an assistant that evaluates how well the customer service agent \
answers a user question by looking at the context that the customer service \
agent is using to generate its response.
一般来说,系统级别的信息就是上下文(context),从模型的角度来说,所有输入的东西都是在context的支配下工作的。

上面这个方法基于传入的system_message和user_message,调用方法get_completion_from_messages获得返回的response:

调用方法并打印response如下:
二、关于prompt内部工作机制
训练GPT系列大模型时,一个基本的能力是预测下一个词(word),那模型为什么能根据我们提供的prompt做出响应?譬如GPT-3,它是根据前面的内容来产出下一个word,前面的内容你都可以认为是prompt。

这个问题的本质是GPT-3/GPT-4是如何训练的,在已有的一个基础的大模型(base LLM)的前提条件下,会经历以下几个核心步骤:
-以一问一答的方式提供样例数据给这个base LLM
-由data contractor人工检查LLM的输出(即human-rating操作),看什么是有用的,什么是没用的
-使用RLHF来调整模型对产生更高rating的输出增加概率
经过上述步骤后会导致我们输入一个prompt(譬如上面说到的evalution使用的看起来有点复杂的prompt)后,会产生相应的结果。

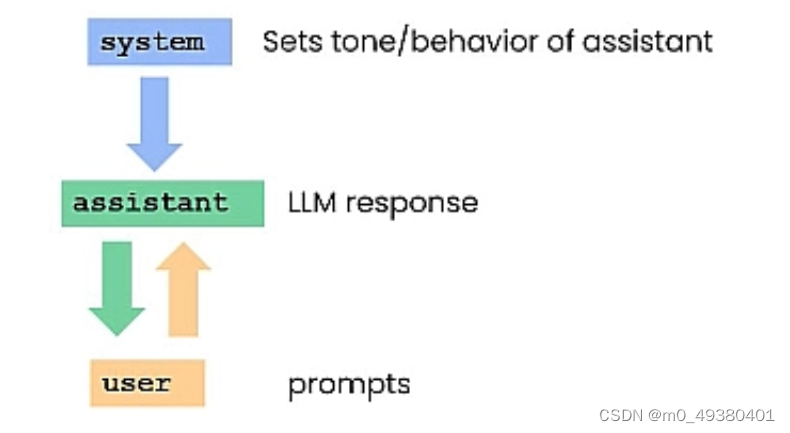
用户在不断地与对话机器人进行交互时,对话机器人在产出结果时至少要考虑两个层面的东西:一是用户输入的内容,二是系统的设定。
Prompt的使用形式有如下几种:
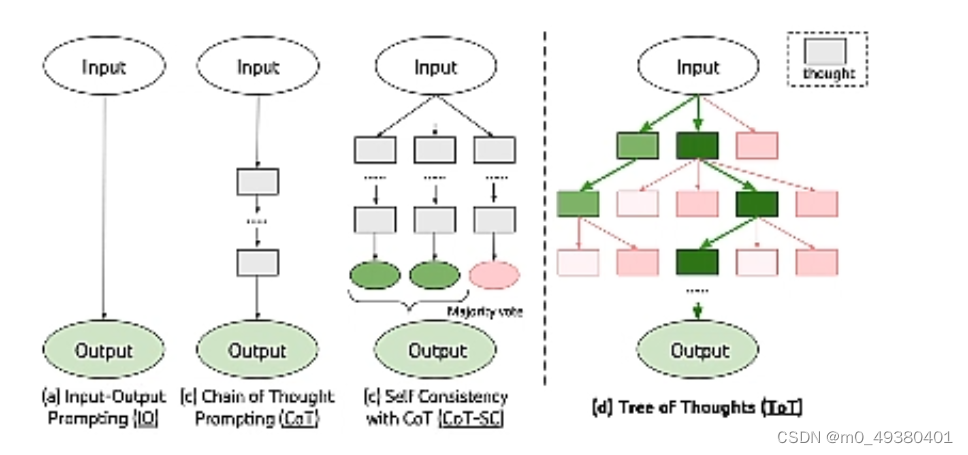
-问答的形式,给一个输入,返回一个输出
-Chain of Thought(CoT)
-Self Consistency with CoT(CoT-SC)
-Tree of Thoughts(ToT),根据用户的输入产生一个树状结构,每一层表示针对上面的节点的prompt或者step产生的结果,譬如第一层针对输入可能会产生不同的结果,然后层层递推,其中存在一个evaluation system,就是判断哪个路径是最相关或者说产出的结果最能够完成用户指定的问题或者任务。
三、从一篇论文来剖析prompt
我们需要思考在一个prompt中,有哪些因素能够影响到一个prompt的功能,另外也要考虑如何使一个prompt最小化,因为这涉及到tokens的使用数量,另外如果信息太多也会干扰到模型对信息的“理解”(这里的“理解”指的是一种形式上的理解,本质上来说模型是无法像人类一样真正理解我们提供的信息的)。
下面这篇论文很重要,提出了几个核心的论述:
-在输入的一个prompt中,“factual patterns”的存在对于CoT的成功来说并不重要
-对于模型来说,中间的步骤(intermediate steps)会作为灯塔信号,让模型参照用户输入中的符号(symbols)构成的patterns来产出结果,模型表现出的仅仅是一种形式上的推理论证
-模型在训练时会获得commonsense knowledge and meaning,从而帮助模型在用户输入的文本形式的prompt中找到patterns
-通过试验分析揭示了在text和patterns之间存在类似生物间相互依赖的一种关系,模型会从文本中基于常识获取patterns,patterns反过来会强化模型对任务进行形式上的理解和指导结果信息的生成
-你能够尽量去裁剪prompt,只留下关键的信息,基于常识依旧能够表达patterns,这些patterns能够指导模型“理解”prompt指定的任务来生成结果
-prompt中的符号的具体形式(exact type of symbols)不影响模型的表现
-CoT帮助模型以prompt为例来学习其中的patterns,然后为任务生成正确的tokens
