手机版网站设计案例网络营销的模式有哪些
目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、案例实现
- 构建Diffusion模型
- 位置向量
- ResNet/ConvNeXT块
- Attention模块
- 组归一化
- 条件U-Net
- 正向扩散
- 数据准备与处理
- 采样
- 训练过程
- 推理过程(从模型中采样)
本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。
本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确保执行环境安装了GUI界面。
关于扩散模型(Diffusion Models)有很多种理解,本文的介绍是基于denoising diffusion probabilistic model (DDPM),DDPM已经在(无)条件图像/音频/视频生成领域取得了较多显著的成果,现有的比较受欢迎的的例子包括由OpenAI主导的GLIDE和DALL-E 2、由海德堡大学主导的潜在扩散和由Google Brain主导的图像生成。
实际上生成模型的扩散概念已经在(Sohl-Dickstein et al., 2015)中介绍过。然而,直到(Song et al., 2019)(斯坦福大学)和(Ho et al., 2020)(在Google Brain)才各自独立地改进了这种方法。
本文是在Phil Wang基于PyTorch框架的复现的基础上(而它本身又是基于TensorFlow实现),迁移到MindSpore AI框架上实现的。

如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
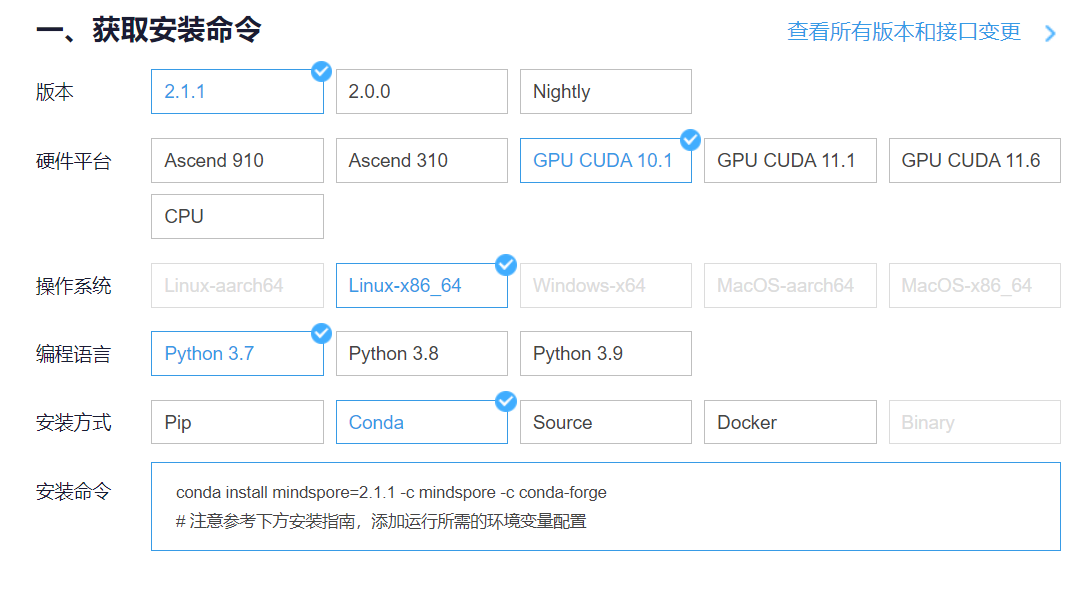
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.1.1版本,可以在昇思教程中进入ModelArts官网
选择下方CodeLab立即体验
等待环境搭建完成
2.使用CodeLab体验Notebook实例
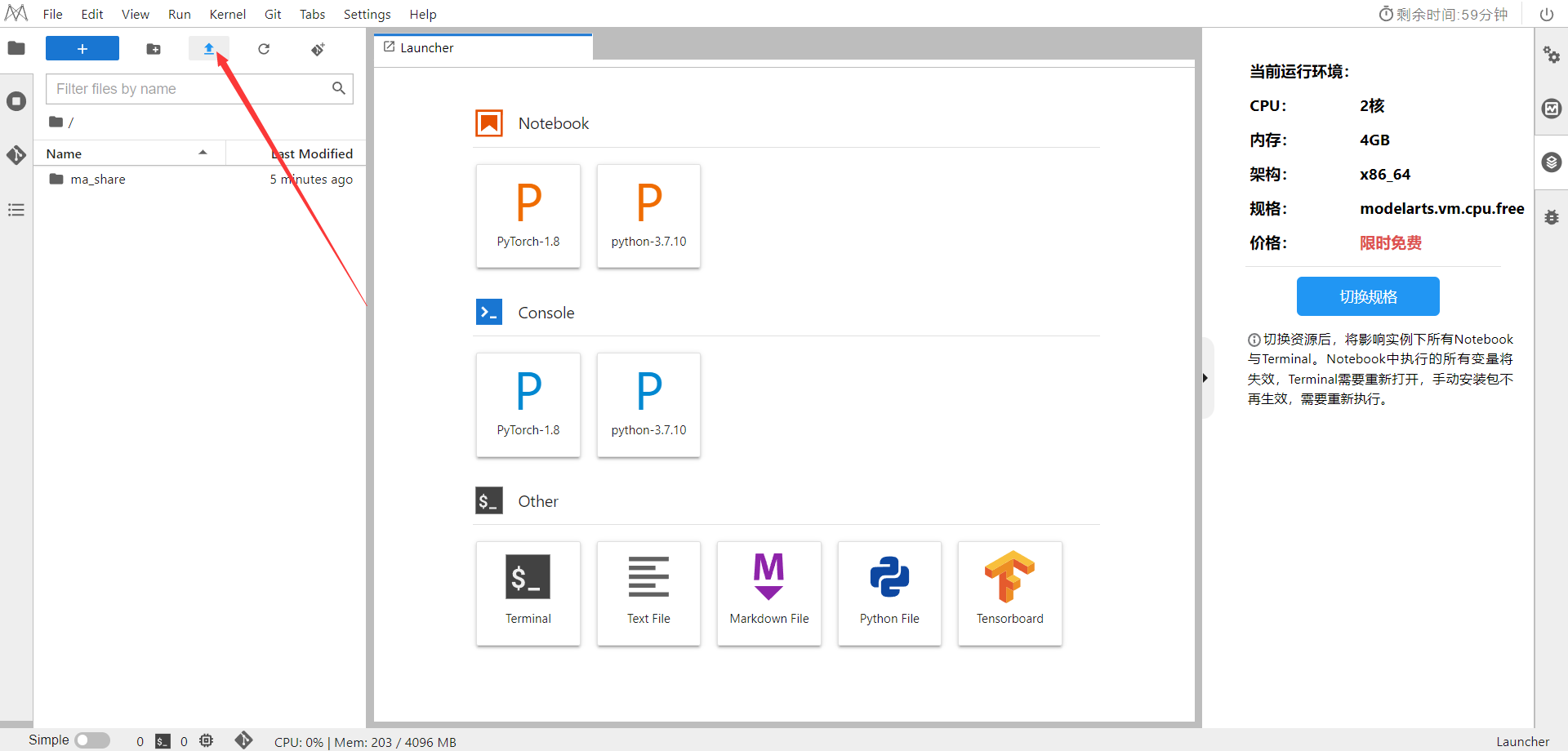
下载NoteBook样例代码,Diffusion扩散模型 ,.ipynb为样例代码

选择ModelArts Upload Files上传.ipynb文件
选择Kernel环境
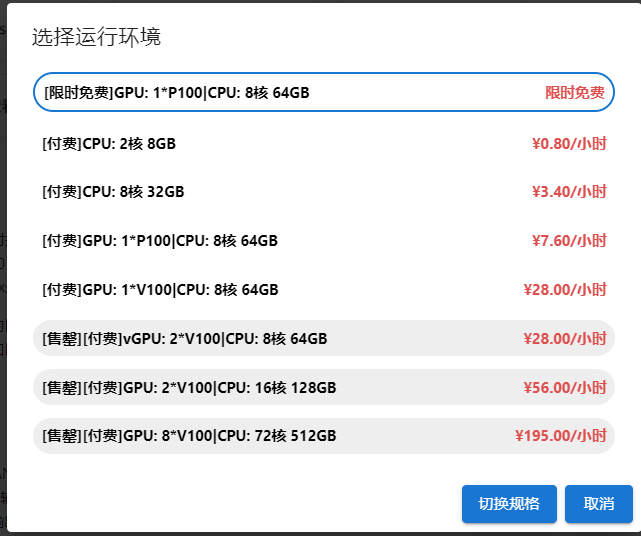
切换至GPU环境,切换成第一个限时免费
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
conda update -n base -c defaults conda
安装MindSpore 2.1 GPU版本
conda install mindspore=2.1.1 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
安装下载download
pip install download
二、案例实现
实验开始之前请确保安装并导入所需的库(假设您已经安装了MindSpore、download、dataset、matplotlib以及tqdm)。
import math
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
import numpy as np
from multiprocessing import cpu_count
from download import downloadimport mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor, Parameter
from mindspore import dtype as mstype
from mindspore.dataset.vision import Resize, Inter, CenterCrop, ToTensor, RandomHorizontalFlip, ToPIL
from mindspore.common.initializer import initializer
from mindspore.amp import DynamicLossScalerms.set_seed(0)
构建Diffusion模型
def rearrange(head, inputs):b, hc, x, y = inputs.shapec = hc // headreturn inputs.reshape((b, head, c, x * y))def rsqrt(x):res = ops.sqrt(x)return ops.inv(res)def randn_like(x, dtype=None):if dtype is None:dtype = x.dtyperes = ops.standard_normal(x.shape).astype(dtype)return resdef randn(shape, dtype=None):if dtype is None:dtype = ms.float32res = ops.standard_normal(shape).astype(dtype)return resdef randint(low, high, size, dtype=ms.int32):res = ops.uniform(size, Tensor(low, dtype), Tensor(high, dtype), dtype=dtype)return resdef exists(x):return x is not Nonedef default(val, d):if exists(val):return valreturn d() if callable(d) else ddef _check_dtype(d1, d2):if ms.float32 in (d1, d2):return ms.float32if d1 == d2:return d1raise ValueError('dtype is not supported.')class Residual(nn.Cell):def __init__(self, fn):super().__init__()self.fn = fndef construct(self, x, *args, **kwargs):return self.fn(x, *args, **kwargs) + x定义了上采样和下采样操作的别名。
def Upsample(dim):return nn.Conv2dTranspose(dim, dim, 4, 2, pad_mode="pad", padding=1)def Downsample(dim):return nn.Conv2d(dim, dim, 4, 2, pad_mode="pad", padding=1)位置向量
由于神经网络的参数在时间(噪声水平)上共享,作者使用正弦位置嵌入来编码t
,灵感来自Transformer(Vaswani et al., 2017)。对于批处理中的每一张图像,神经网络“知道”它在哪个特定时间步长(噪声水平)上运行。
SinusoidalPositionEmbeddings模块采用(batch_size, 1)形状的张量作为输入(即批处理中几个有噪声图像的噪声水平),并将其转换为(batch_size, dim)形状的张量,其中dim是位置嵌入的尺寸。然后,我们将其添加到每个剩余块中。
class SinusoidalPositionEmbeddings(nn.Cell):def __init__(self, dim):super().__init__()self.dim = dimhalf_dim = self.dim // 2emb = math.log(10000) / (half_dim - 1)emb = np.exp(np.arange(half_dim) * - emb)self.emb = Tensor(emb, ms.float32)def construct(self, x):emb = x[:, None] * self.emb[None, :]emb = ops.concat((ops.sin(emb), ops.cos(emb)), axis=-1)return embResNet/ConvNeXT块
接下来,我们定义U-Net模型的核心构建块。DDPM作者使用了一个Wide ResNet块(Zagoruyko et al., 2016),但Phil Wang决定添加ConvNeXT(Liu et al., 2022)替换ResNet,因为后者在图像领域取得了巨大成功。
在最终的U-Net架构中,可以选择其中一个或另一个,本文选择ConvNeXT块构建U-Net模型。
class Block(nn.Cell):def __init__(self, dim, dim_out, groups=1):super().__init__()self.proj = nn.Conv2d(dim, dim_out, 3, pad_mode="pad", padding=1)self.proj = c(dim, dim_out, 3, padding=1, pad_mode='pad')self.norm = nn.GroupNorm(groups, dim_out)self.act = nn.SiLU()def construct(self, x, scale_shift=None):x = self.proj(x)x = self.norm(x)if exists(scale_shift):scale, shift = scale_shiftx = x * (scale + 1) + shiftx = self.act(x)return xclass ConvNextBlock(nn.Cell):def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):super().__init__()self.mlp = (nn.SequentialCell(nn.GELU(), nn.Dense(time_emb_dim, dim))if exists(time_emb_dim)else None)self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, group=dim, pad_mode="pad")self.net = nn.SequentialCell(nn.GroupNorm(1, dim) if norm else nn.Identity(),nn.Conv2d(dim, dim_out * mult, 3, padding=1, pad_mode="pad"),nn.GELU(),nn.GroupNorm(1, dim_out * mult),nn.Conv2d(dim_out * mult, dim_out, 3, padding=1, pad_mode="pad"),)self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()def construct(self, x, time_emb=None):h = self.ds_conv(x)if exists(self.mlp) and exists(time_emb):assert exists(time_emb), "time embedding must be passed in"condition = self.mlp(time_emb)condition = condition.expand_dims(-1).expand_dims(-1)h = h + conditionh = self.net(h)return h + self.res_conv(x)Attention模块
接下来,我们定义SiLU模块,DDPM作者将其添加到卷积块之间。SiLU是著名的Transformer架构(Vaswani et al., 2017),在人工智能的各个领域都取得了巨大的成功,从NLP到蛋白质折叠。Phil Wang使用了两种注意力变体:一种是常规的multi-head self-attention(如Transformer中使用的),另一种是LinearAttention(Shen et al., 2018),其时间和内存要求在序列长度上线性缩放,而不是在常规注意力中缩放。
class Attention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * headsself.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)self.to_out = nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True)self.map = ops.Map()self.partial = ops.Partial()def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)q = q * self.scale# 'b h d i, b h d j -> b h i j'sim = ops.bmm(q.swapaxes(2, 3), k)attn = ops.softmax(sim, axis=-1)# 'b h i j, b h d j -> b h i d'out = ops.bmm(attn, v.swapaxes(2, 3))out = out.swapaxes(-1, -2).reshape((b, -1, h, w))return self.to_out(out)class LayerNorm(nn.Cell):def __init__(self, dim):super().__init__()self.g = Parameter(initializer('ones', (1, dim, 1, 1)), name='g')def construct(self, x):eps = 1e-5var = x.var(1, keepdims=True)mean = x.mean(1, keep_dims=True)return (x - mean) * rsqrt((var + eps)) * self.gclass LinearAttention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * headsself.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)self.to_out = nn.SequentialCell(nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True),LayerNorm(dim))self.map = ops.Map()self.partial = ops.Partial()def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)q = ops.softmax(q, -2)k = ops.softmax(k, -1)q = q * self.scalev = v / (h * w)# 'b h d n, b h e n -> b h d e'context = ops.bmm(k, v.swapaxes(2, 3))# 'b h d e, b h d n -> b h e n'out = ops.bmm(context.swapaxes(2, 3), q)out = out.reshape((b, -1, h, w))return self.to_out(out)组归一化
DDPM作者将U-Net的卷积/注意层与群归一化(Wu et al., 2018)。下面,我们定义一个PreNorm类,将用于在注意层之前应用groupnorm。
class PreNorm(nn.Cell):def __init__(self, dim, fn):super().__init__()self.fn = fnself.norm = nn.GroupNorm(1, dim)def construct(self, x):x = self.norm(x)return self.fn(x)条件U-Net
class Unet(nn.Cell):def __init__(self,dim,init_dim=None,out_dim=None,dim_mults=(1, 2, 4, 8),channels=3,with_time_emb=True,convnext_mult=2,):super().__init__()self.channels = channelsinit_dim = default(init_dim, dim // 3 * 2)self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True)dims = [init_dim, *map(lambda m: dim * m, dim_mults)]in_out = list(zip(dims[:-1], dims[1:]))block_klass = partial(ConvNextBlock, mult=convnext_mult)if with_time_emb:time_dim = dim * 4self.time_mlp = nn.SequentialCell(SinusoidalPositionEmbeddings(dim),nn.Dense(dim, time_dim),nn.GELU(),nn.Dense(time_dim, time_dim),)else:time_dim = Noneself.time_mlp = Noneself.downs = nn.CellList([])self.ups = nn.CellList([])num_resolutions = len(in_out)for ind, (dim_in, dim_out) in enumerate(in_out):is_last = ind >= (num_resolutions - 1)self.downs.append(nn.CellList([block_klass(dim_in, dim_out, time_emb_dim=time_dim),block_klass(dim_out, dim_out, time_emb_dim=time_dim),Residual(PreNorm(dim_out, LinearAttention(dim_out))),Downsample(dim_out) if not is_last else nn.Identity(),]))mid_dim = dims[-1]self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):is_last = ind >= (num_resolutions - 1)self.ups.append(nn.CellList([block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),block_klass(dim_in, dim_in, time_emb_dim=time_dim),Residual(PreNorm(dim_in, LinearAttention(dim_in))),Upsample(dim_in) if not is_last else nn.Identity(),]))out_dim = default(out_dim, channels)self.final_conv = nn.SequentialCell(block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1))def construct(self, x, time):x = self.init_conv(x)t = self.time_mlp(time) if exists(self.time_mlp) else Noneh = []for block1, block2, attn, downsample in self.downs:x = block1(x, t)x = block2(x, t)x = attn(x)h.append(x)x = downsample(x)x = self.mid_block1(x, t)x = self.mid_attn(x)x = self.mid_block2(x, t)len_h = len(h) - 1for block1, block2, attn, upsample in self.ups:x = ops.concat((x, h[len_h]), 1)len_h -= 1x = block1(x, t)x = block2(x, t)x = attn(x)x = upsample(x)return self.final_conv(x)正向扩散
def linear_beta_schedule(timesteps):beta_start = 0.0001beta_end = 0.02return np.linspace(beta_start, beta_end, timesteps).astype(np.float32)# 扩散200步
timesteps = 200# 定义 beta schedule
betas = linear_beta_schedule(timesteps=timesteps)# 定义 alphas
alphas = 1. - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
alphas_cumprod_prev = np.pad(alphas_cumprod[:-1], (1, 0), constant_values=1)sqrt_recip_alphas = Tensor(np.sqrt(1. / alphas))
sqrt_alphas_cumprod = Tensor(np.sqrt(alphas_cumprod))
sqrt_one_minus_alphas_cumprod = Tensor(np.sqrt(1. - alphas_cumprod))# 计算 q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)p2_loss_weight = (1 + alphas_cumprod / (1 - alphas_cumprod)) ** -0.
p2_loss_weight = Tensor(p2_loss_weight)def extract(a, t, x_shape):b = t.shape[0]out = Tensor(a).gather(t, -1)return out.reshape(b, *((1,) * (len(x_shape) - 1)))用猫图像说明如何在扩散过程的每个时间步骤中添加噪音。
# 下载猫猫图像
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/image_cat.zip'
path = download(url, './', kind="zip", replace=True)from PIL import Imageimage = Image.open('./image_cat/jpg/000000039769.jpg')
base_width = 160
image = image.resize((base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))))
image.show()噪声被添加到mindspore张量中,而不是Pillow图像。我们将首先定义图像转换,允许我们从PIL图像转换到mindspore张量(我们可以在其上添加噪声),反之亦然。
from mindspore.dataset import ImageFolderDatasetimage_size = 128
transforms = [Resize(image_size, Inter.BILINEAR),CenterCrop(image_size),ToTensor(),lambda t: (t * 2) - 1
]path = './image_cat'
dataset = ImageFolderDataset(dataset_dir=path, num_parallel_workers=cpu_count(),extensions=['.jpg', '.jpeg', '.png', '.tiff'],num_shards=1, shard_id=0, shuffle=False, decode=True)
dataset = dataset.project('image')
transforms.insert(1, RandomHorizontalFlip())
dataset_1 = dataset.map(transforms, 'image')
dataset_2 = dataset_1.batch(1, drop_remainder=True)
x_start = next(dataset_2.create_tuple_iterator())[0]
print(x_start.shape)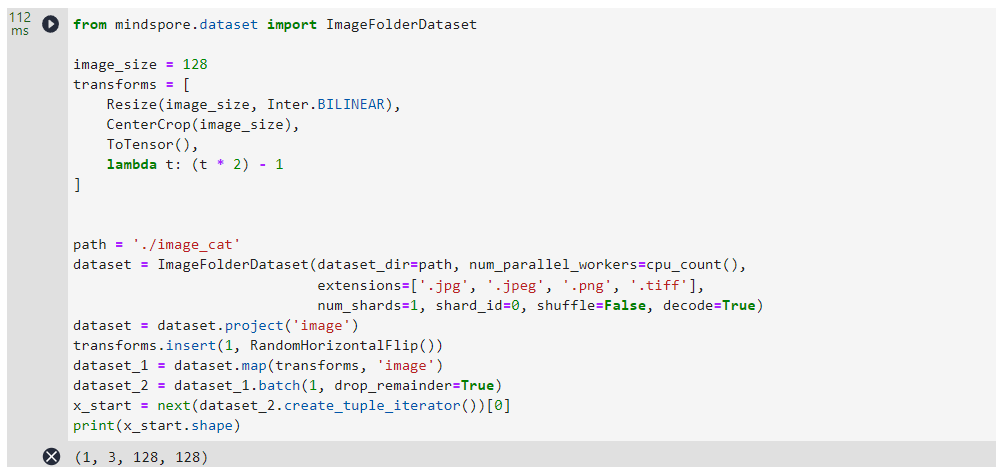
定义了反向变换,它接收一个包含 [−1,1]中的张量,并将它们转回 PIL 图像:
import numpy as npreverse_transform = [lambda t: (t + 1) / 2,lambda t: ops.permute(t, (1, 2, 0)), # CHW to HWClambda t: t * 255.,lambda t: t.asnumpy().astype(np.uint8),ToPIL()
]def compose(transform, x):for d in transform:x = d(x)return xreverse_image = compose(reverse_transform, x_start[0])
reverse_image.show()我们现在可以定义前向扩散过程,如本文所示:
def q_sample(x_start, t, noise=None):if noise is None:noise = randn_like(x_start)return (extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start +extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)让我们在特定的时间步长上测试它:
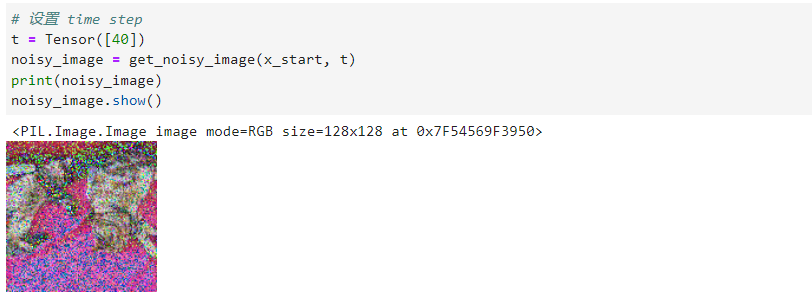
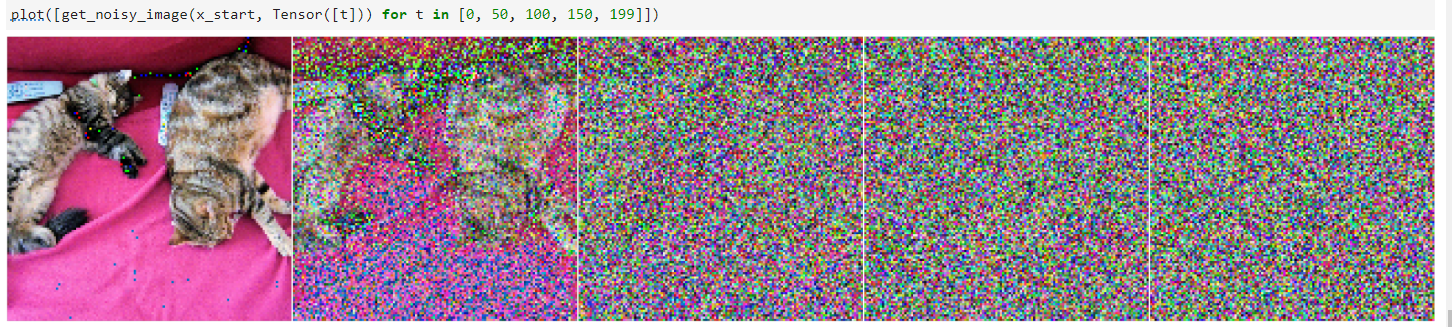
让我们为不同的时间步骤可视化此情况:
可以定义给定模型的损失函数,如下所示:
def p_losses(unet_model, x_start, t, noise=None):if noise is None:noise = randn_like(x_start)x_noisy = q_sample(x_start=x_start, t=t, noise=noise)predicted_noise = unet_model(x_noisy, t)loss = nn.SmoothL1Loss()(noise, predicted_noise)# todoloss = loss.reshape(loss.shape[0], -1)loss = loss * extract(p2_loss_weight, t, loss.shape)return loss.mean()denoise_model将是我们上面定义的U-Net。我们将在真实噪声和预测噪声之间使用Huber损失。
数据准备与处理
在这里我们定义一个正则数据集。数据集可以来自简单的真实数据集的图像组成,如Fashion-MNIST、CIFAR-10或ImageNet,其中线性缩放为 [−1,1]
。
# 下载MNIST数据集
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip'
path = download(url, './', kind="zip", replace=True)
from mindspore.dataset import FashionMnistDatasetimage_size = 28
channels = 1
batch_size = 16fashion_mnist_dataset_dir = "./dataset"
dataset = FashionMnistDataset(dataset_dir=fashion_mnist_dataset_dir, usage="train", num_parallel_workers=cpu_count(), shuffle=True, num_shards=1, shard_id=0)接下来定义一个transform操作,将在整个数据集上动态应用该操作。该操作应用一些基本的图像预处理:随机水平翻转、重新调整,最后使它们的值在 [−1,1]范围内。
transforms = [RandomHorizontalFlip(),ToTensor(),lambda t: (t * 2) - 1
]dataset = dataset.project('image')
dataset = dataset.shuffle(64)
dataset = dataset.map(transforms, 'image')
dataset = dataset.batch(16, drop_remainder=True)x = next(dataset.create_dict_iterator())
print(x.keys())
采样
def p_sample(model, x, t, t_index):betas_t = extract(betas, t, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)if t_index == 0:return model_meanposterior_variance_t = extract(posterior_variance, t, x.shape)noise = randn_like(x)return model_mean + ops.sqrt(posterior_variance_t) * noisedef p_sample_loop(model, shape):b = shape[0]# 从纯噪声开始img = randn(shape, dtype=None)imgs = []for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):img = p_sample(model, img, ms.numpy.full((b,), i, dtype=mstype.int32), i)imgs.append(img.asnumpy())return imgsdef sample(model, image_size, batch_size=16, channels=3):return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))请注意,上面的代码是原始实现的简化版本。
训练过程
# 定义动态学习率
lr = nn.cosine_decay_lr(min_lr=1e-7, max_lr=1e-4, total_step=10*3750, step_per_epoch=3750, decay_epoch=10)# 定义 Unet模型
unet_model = Unet(dim=image_size,channels=channels,dim_mults=(1, 2, 4,)
)name_list = []
for (name, par) in list(unet_model.parameters_and_names()):name_list.append(name)
i = 0
for item in list(unet_model.trainable_params()):item.name = name_list[i]i += 1# 定义优化器
optimizer = nn.Adam(unet_model.trainable_params(), learning_rate=lr)
loss_scaler = DynamicLossScaler(65536, 2, 1000)# 定义前向过程
def forward_fn(data, t, noise=None):loss = p_losses(unet_model, data, t, noise)return loss# 计算梯度
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False)# 梯度更新
def train_step(data, t, noise):loss, grads = grad_fn(data, t, noise)optimizer(grads)return lossimport timeepochs = 10for epoch in range(epochs):begin_time = time.time()for step, batch in enumerate(dataset.create_tuple_iterator()):unet_model.set_train()batch_size = batch[0].shape[0]t = randint(0, timesteps, (batch_size,), dtype=ms.int32)noise = randn_like(batch[0])loss = train_step(batch[0], t, noise)if step % 500 == 0:print(" epoch: ", epoch, " step: ", step, " Loss: ", loss)end_time = time.time()times = end_time - begin_timeprint("training time:", times, "s")# 展示随机采样效果unet_model.set_train(False)samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)plt.imshow(samples[-1][5].reshape(image_size, image_size, channels), cmap="gray")
print("Training Success!")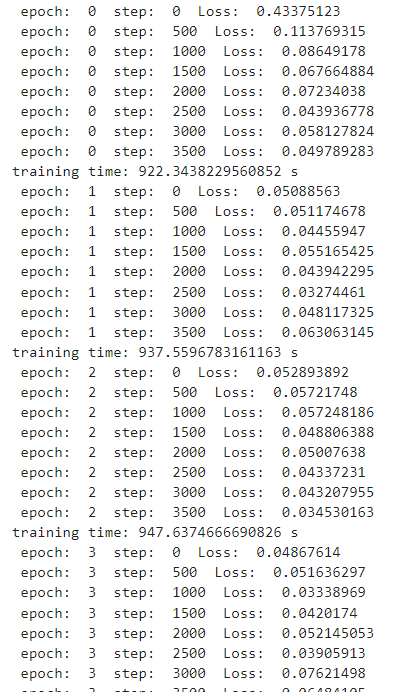
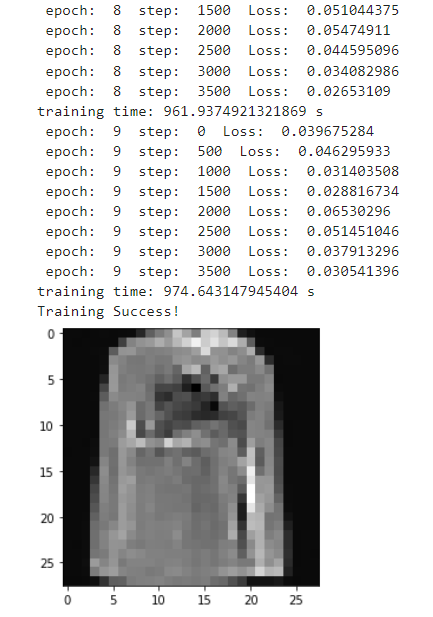
推理过程(从模型中采样)
# 采样64个图片
unet_model.set_train(False)
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)# 展示一个随机效果
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")创建去噪过程的gif:
import matplotlib.animation as animationrandom_index = 53fig = plt.figure()
ims = []
for i in range(timesteps):im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)ims.append([im])animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=100)
animate.save('diffusion.gif')
plt.show()