做网站大模板建站教程
一、分布式的思想
不管是数据也好,计算也好,都没有最大的电脑,而是多个小电脑组合而成。
存储:将3T的文件拆分成若干个小文件,例如每500M一个小文件,将这些小文件存储在不同的机器上 。 -- HDFS
计算:
分:将一个大的任务拆分成多个小的任务,每台机器处理一 个小的任务,并行处理
合:将多个小任务的结果最终再合并生成最终的结果进行返 回问题解决 。
--MapReduce (Hive)
Spark 解决不了存储的问题,spark是搞计算的。你学习了spark,以前的计算引擎都可以作废了。Spark可以做离线的计算可以做准实时(实时计算目前使用Flink比较多)
发展 :计算引擎 ---存储还得是hdfs
第一代计算引擎:MapReduce:用廉价机器实现分布式大数据处理
第二代计算引擎:Tez:基于MR优化了DAG,性能比MR快一些
第三代计算引擎:Spark:优先使用内存式计算引擎 ,国内目前主要应用的离线计算引擎
第四代计算引擎:Flink:实时流式计算引擎 , 国内目前最主流实时计算引擎
二、Spark简介 [火花]
1、发展历程
DataBricks官网:https://databricks.com/spark/about
spark的诞生其实是因为MR计算引擎太慢了。
MR计算是基于磁盘的,Spark计算是基于内存的。
spark的发展历程:
2009年,Spark诞生于伯克利AMPLab,伯克利大学的研究性项目。
2014年2月成为Apache顶级项目,同年5月发布Spark 1.0正式版本
2018年Spark2.4.0发布,成为全球最大的开源项目,目前是Apache中的顶级项目之一。
2020年6月Spark发布3.0.0正式版,目前学习的就是3.x
apache给它分配的网站:Apache Spark™ - Unified Engine for large-scale data analytics
定义:基于内存式计算的分布式的统一化的数据分析引擎。
分析引擎:hive 、spark、presto、impala 等。所谓的引擎,狭义理解就是sql。
2、spark能做什么?
实现离线数据批处理:类似于MapReduce、Pandas,写代码做处理:代码类的离线数据处理
实现交互式即时数据查询:类似于Hive、Presto、Impala,使 用SQL做即席查询分析:SQL类的离线数据处理
实现实时数据处理:类似于Storm、Flink实现分布式的实时计算:代码类实时计算或者SQL类的实时计算
实现机器学习的开发:代替传统一些机器学习工具
3、spark有哪些部分组成?
Hadoop的组成部分:common、MapReduce、Hdfs、Yarn
Spark Core:Spark最核心的模块,可以基于多种语言实现代码类的离线开发 【类似于MR】
Spark SQL:类似于Hive,基于SQL进行开发,SQL会转换为SparkCore离线程序 【类似Hive】
Spark Streaming:基于SparkCore之上构建了准实时的计算模块 【淘汰了】
Struct Streaming:基于SparkSQL之上构建了结构化实时计算模块 【替代了Spark Streaming】
Spark ML lib:机器学习算法库,提供各种机器学习算法工具,可以基于SparkCore或者SparkSQL实现开发。

开发语言:Python、SQL、Scala、Java、R【Spark的源码是通过Scala语言开发的】
一个软件是什么语言写的,跟什么语言可以操作这个软件是两回事儿。
Scala 语言是基于java实现的,底层也需要虚拟机。
4、spark运行有五种模式【重点】
本地模式:Local:一般用于做测试,验证代码逻辑,不是分布式运行,只会启动1个进程来运行所有任务。
集群模式:Cluster:一般用于生产环境,用于实现PySpark程序的分布式的运行
Standalone:Spark自带的分布式资源平台,功能类似于YARN
YARN:Spark on YARN,将Spark程序提交给YARN来运行,工作中主要使用的模式
Mesos:类似于YARN,国外见得多,国内基本见不到
K8s:基于分布式容器的资源管理平台,运维层面的工具。
解释:Spark是一个分布式的分析引擎,所以它部署的时候是分布式的,有用主节点,从节点这些内容。Standalone使用的是Spark自带的分布式资源平台,但是假如一个公司已经有Yarn分析平台了,就没必要再搭建spark分析平台,浪费资源。
学习过程中:本地模式 --> Standalone --> YARN ,将来spark在yarn上跑。
5、spark 为什么比MR快?
1、MR不支持DAG【有向无环图】,计算过程是固定,一个MR 只有1个Map和1个Reduce构成。 一个Map和Reduce是一个过程,和另一个Map和Reduce是不一样的。
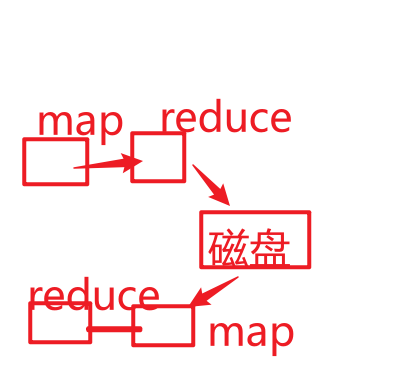
从落地到磁盘的那一刻,上一个过程已经结束了,下一个过程和上一个过程没有关系了。
2、MR是一个基于磁盘的计算框架,读写效率比较低
3、MR的Task计算是进程级别的,每次运行一个Task都需要启动一个进程,然后运行结束还是释放进程,比较慢。【一个进程可以包含多个线程,比如qq是一个进程,发消息,传文件是一个个线程】
MapTask:进程
ReduceTask:进程
进程启动和销毁是比较耗时的
spark为什么那么快?
1、Spark支持DAG,一个Spark程序中的过程是不固定,由代码 所决定。
2、Task任务都是线程级别的
3、计算是基于内存的。


总结:1.数据结构一个HDFS,一个是RDD
2.计算流结构一个用的MR,一个是DAG
3.中间存储一个放到磁盘,一个全在内存
4.运行方式一个用进程,一个是线程
一、Standalone集群环境安装
1、理解Standalone集群架构
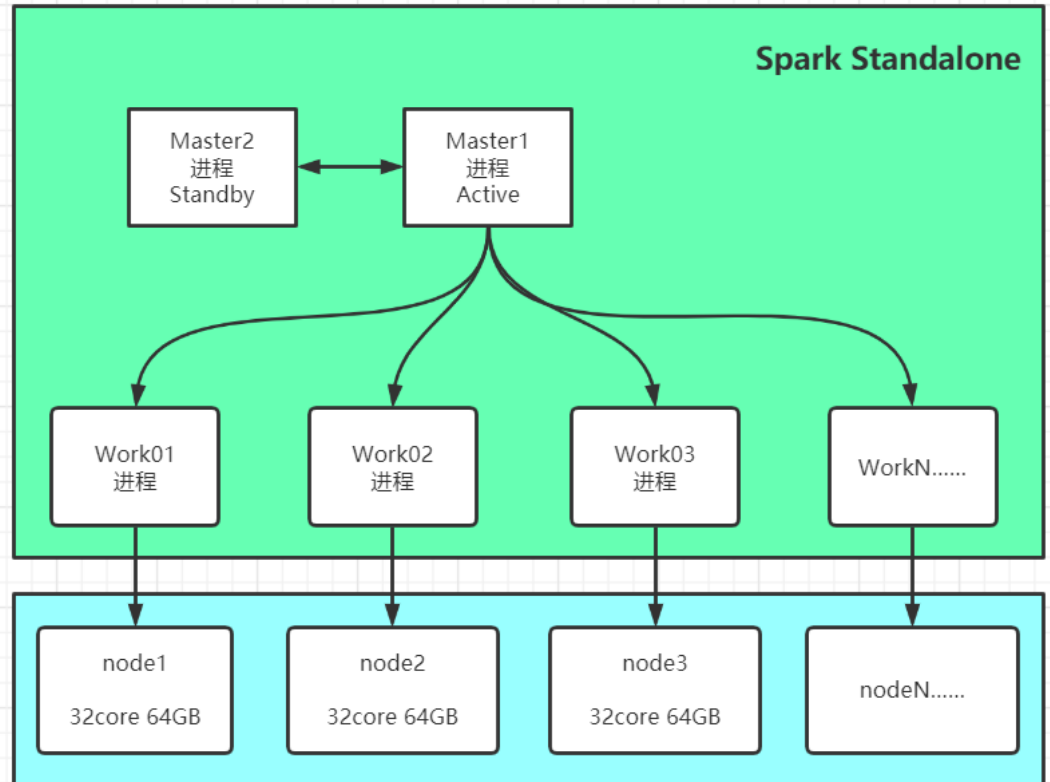

架构:普通分布式主从架构
主:Master:管理节点:管理从节点、接客、资源管理和任务
调度,等同于YARN中的ResourceManager
从:Worker:计算节点:负责利用自己节点的资源运行主节点
分配的任务
功能:提供分布式资源管理和任务调度,基本上与YARN是一致的
看着很像Yarn,其实作用跟yarn一样,是spark自带的计算平台。
每一台服务器上都要安装Annaconda ,否则会出现python3 找不到的错误!!
2、Standalone集群部署
第一步:将bigdata02和bigdata03安装Annaconda,因为里面有python3环境,假如没有安装的话,就报这个错误: