成华区建设局网站武汉seo网站排名
目录
1. 下载dataset
2. 读取并做可视化
3. 源码阅读
3.1 读取点云数据-bin格式
3.2 读取标注数据-.label文件
3.3 读取配置
3.4 test
3.5 train
1. 下载dataset
以SemanticKITTI为例。下载链接:http://semantic-kitti.org/dataset.html#download

把上面三个下载下来。

同级目录下解压
unzip data_odometry_labels.zip
unzip data_odometry_velodyne.zip
unzip data_odometry_calib.zip解压后文件夹形式:
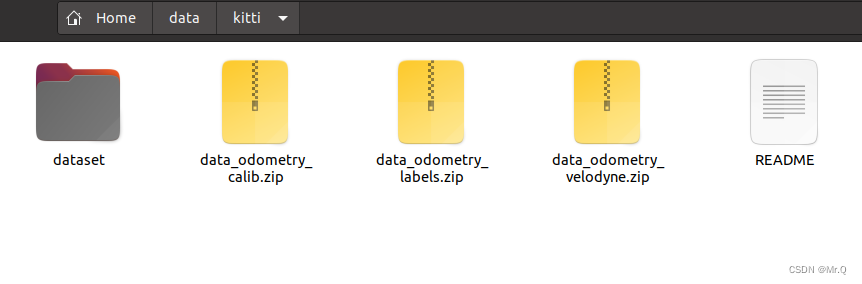
2. 读取并做可视化
import open3d.ml.torch as ml3d # or open3d.ml.tf as ml3d# construct a dataset by specifying dataset_path
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/home/zxq/data/kitti')# get the 'all' split that combines training, validation and test set
all_split = dataset.get_split('all')# print the attributes of the first datum
print(all_split.get_attr(0))# print the shape of the first point cloud
print(all_split.get_data(0)['point'].shape)# show the first 100 frames using the visualizer
vis = ml3d.vis.Visualizer()
vis.visualize_dataset(dataset, 'all', indices=range(100))点云分割数据集SemanticKITTI
3. 源码阅读
3.1 读取点云数据-bin格式
SemanticKITTI的点云和标注数据都是二进制文件。
datatsets/utils/dataprocessing.py
@staticmethoddef load_pc_kitti(pc_path): # "./000000.bin"scan = np.fromfile(pc_path, dtype=np.float32) # (num_pt*4,)scan = scan.reshape((-1, 4)) # # (num_pt,4)# points = scan[:, 0:3] # get xyzpoints = scanreturn points3.2 读取标注数据-.label文件
def load_label_kitti(label_path, remap_lut):label = np.fromfile(label_path, dtype=np.uint32)label = label.reshape((-1))sem_label = label & 0xFFFF # semantic label in lower half inst_label = label >> 16 # instance id in upper halfassert ((sem_label + (inst_label << 16) == label).all())sem_label = remap_lut[sem_label]return sem_label.astype(np.int32)3.3 读取配置
模型,数据集,流程配置都保存在ml3d/configs/*.yaml文件中。读取方式:
import open3d.ml as _ml3d
import open3d.ml.torch as ml3d # or open3d.ml.tf as ml3dframework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)# fetch the classes by the name
Pipeline = _ml3d.utils.get_module("pipeline", cfg.pipeline.name, framework)
Model = _ml3d.utils.get_module("model", cfg.model.name, framework)
Dataset = _ml3d.utils.get_module("dataset", cfg.dataset.name)# use the arguments in the config file to construct the instances
cfg.dataset['dataset_path'] = "/home/zxq/data/kitti"
dataset = Dataset(cfg.dataset.pop('dataset_path', None), **cfg.dataset)
model = Model(**cfg.model)
pipeline = Pipeline(model, dataset, **cfg.pipeline)3.4 test
import os
import open3d.ml as _ml3d
import open3d.ml.torch as ml3dcfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d.utils.Config.load_from_file(cfg_file)model = ml3d.models.RandLANet(**cfg.model)
cfg.dataset['dataset_path'] = "/home/zxq/data/kitti"
dataset = ml3d.datasets.SemanticKITTI(cfg.dataset.pop('dataset_path', None), **cfg.dataset)
pipeline = ml3d.pipelines.SemanticSegmentation(model, dataset=dataset, device="gpu", **cfg.pipeline)# download the weights.
ckpt_folder = "./logs/"
os.makedirs(ckpt_folder, exist_ok=True)
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os.path.exists(ckpt_path):cmd = "wget {} -O {}".format(randlanet_url, ckpt_path)os.system(cmd)# load the parameters.
pipeline.load_ckpt(ckpt_path=ckpt_path)test_split = dataset.get_split("test")# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
data = test_split.get_data(0)
result = pipeline.run_inference(data)# evaluate performance on the test set; this will write logs to './logs'.
pipeline.run_test()3.5 train
import open3d.ml.torch as ml3dfrom ml3d.torch import RandLANet, SemanticSegmentation# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/home/zxq/data/kitti/', use_cache=True)# create the model with random initialization.
model = RandLANet()pipeline = SemanticSegmentation(model=model, dataset=dataset, max_epoch=100)# prints training progress in the console.
pipeline.run_train()