义乌网站建设联系方式优秀的网络搜索引擎营销案例
研究背景
为通过项目实战增加对命名实体识别的认识,本文找到中科院软件所刘焕勇老师在github上的开源项目,中文电子病例命名实体识别项目MedicalNamedEntityRecognition。对其进行详细解读。
原项目地址:https://github.com/liuhuanyong/MedicalNamedEntityRecognition
修改版项目地址(详细注释):待补充
项目介绍
数据来自CCKS2018的电子病历命名实体识别的评测任务,是对于给定的一组电子病历纯文本文档,识别并抽取出其中与医学临床相关的实体,并将它们归类到预先定义好的类别中。共提供600份标注好的电子病历文本,共需识别含治疗方式、身体部位、疾病症状、医学检查、疾病实体五类实体。
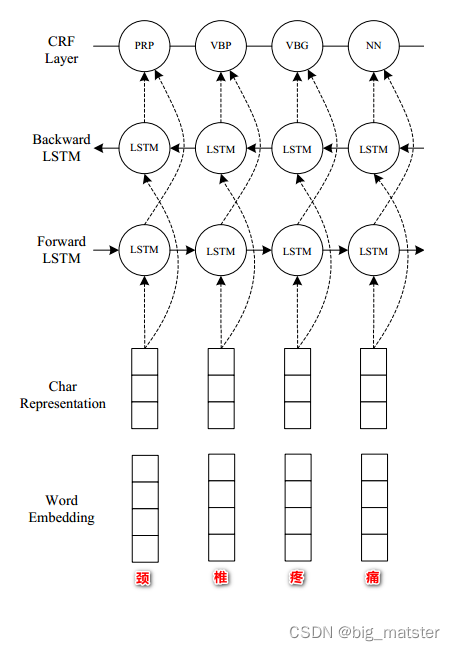
领域命名实体识别问题自然语言处理中经典的序列标注问题, 本项目是采用BiLSTM+CRF构建模型。
病历结构如下图所示:

神经网络结构图
实验数据





import os
class TransferData:def __init__(self):cur = '/'.join(os.path.abspath(__file__).split('/')[:-1]) #获取当前文件地址的上级目录#对分类进行标记self.label_dict = {'检查和检验': 'CHECK','症状和体征': 'SIGNS','疾病和诊断': 'DISEASE','治疗': 'TREATMENT','身体部位': 'BODY'}self.origin_path = os.path.join(cur, 'data_origin') #原始数据地址self.train_filepath = os.path.join(cur, 'train.txt') #转化后的训练数据地址returndef transfer(self):f = open(self.train_filepath, 'w+',encoding='utf-8') #以写入的方式打开训练数据要保存的文件count = 0for root,dirs,files in os.walk(self.origin_path):#for (root, dirs, files) in walk(roots):# roots代表需要遍历的根文件夹;# root表示正在遍历的文件夹的名字(根/子);# dirs记录正在遍历的文件夹下的子文件夹集合;# files记录正在遍历的文件夹中的文件集合for file in files:filepath = os.path.join(root, file)if 'original' not in filepath:continuelabel_filepath = filepath.replace('.txtoriginal','')print(filepath, '\t\t', label_filepath) #data_origin\一般项目\一般项目-1.txtoriginal.txt data_origin\一般项目\一般项目-1.txtcontent = open(filepath,encoding='utf-8').read().strip() #打开案例描述文件,去掉收尾空格res_dict = {}for line in open(label_filepath,encoding='utf-8'): #打开实体类别文件res = line.strip().split(' ') #每个实体描述按空格分隔 ['右髋部',‘21’,‘23’,‘身体部位’]start = int(res[1]) #实体的其实字符位置end = int(res[2]) #实体的结束字符位置label = res[3] #实体类别label_id = self.label_dict.get(label) #返回分类字典中实体类别对应的values,作为实体名称的idfor i in range(start, end+1):if i == start:label_cate = label_id + '-B' #定义实体的首字符else:label_cate = label_id + '-I' #实体的非首字符res_dict[i] = label_cate #构建实体字典{位置index:字符}for indx, char in enumerate(content): #indx文本中字符的位置,char字符char_label = res_dict.get(indx, 'O') #如果indx在字典的key中,则返回字典value;否则返回O,代表非实体print(char, char_label) #字符:字符实体标注f.write(char + '\t' + char_label + '\n')f.close()return
if __name__ == '__main__':handler = TransferData()train_datas = handler.transfer()连接
原文连接