城乡建设委官方网站抖音营销
文章目录
- 1. ODConv
- 1.1 修改
- 1.2 原yaml文件
- 1.3 修改yaml文件样式1
- 1.4 修改yaml文件样式2
- 2. DAT
- 3. 在train下修改模型
1. ODConv
1.1 修改
1. 在ultralytics/nn/models里创建ODConv.py文件。
2. 在ultralytics/nn/task.py中导入from .modules.ODConv import C2f_ODConv,ODConv2d
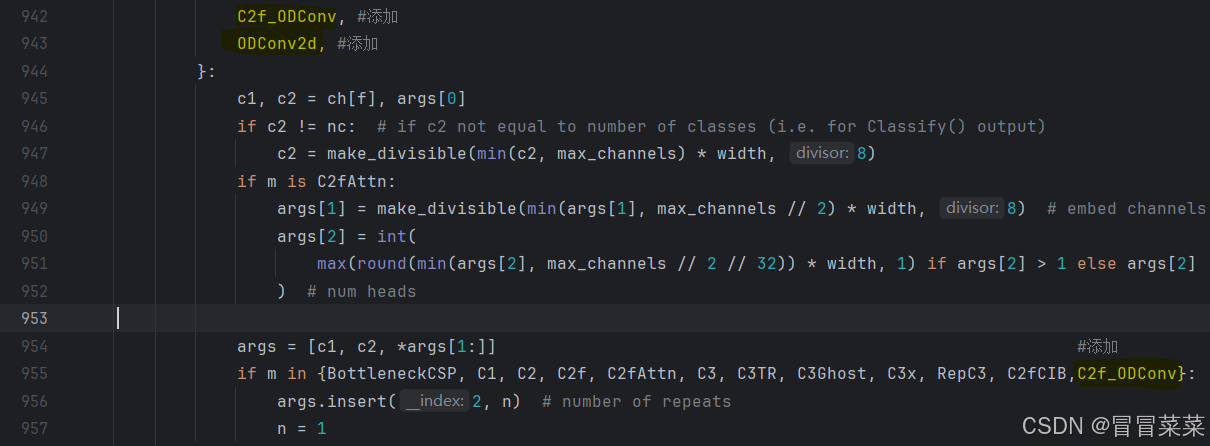
1.2 原yaml文件
在ultralytics/cfg/models/v8/yolov8.yaml里。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.3 修改yaml文件样式1
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_ODConv, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_ODConv, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_ODConv, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.4 修改yaml文件样式2
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, ODConv2d, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, ODConv2d, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, ODConv2d, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, ODConv2d, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, ODConv2d, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, ODConv2d, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
2. DAT
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import einops
from timm.models.layers import to_2tuple, trunc_normal_class LayerNormProxy(nn.Module):def __init__(self, dim):super().__init__()self.norm = nn.LayerNorm(dim)def forward(self, x):x = einops.rearrange(x, 'b c h w -> b h w c')x = self.norm(x)return einops.rearrange(x, 'b h w c -> b c h w')class DAttentionBaseline(nn.Module):def __init__(self, q_size=(224,224), kv_size=(224,224), n_heads=8, n_head_channels=32, n_groups=1,attn_drop=0.0, proj_drop=0.0, stride=1,offset_range_factor=-1, use_pe=True, dwc_pe=True,no_off=False, fixed_pe=False, ksize=9, log_cpb=False):super().__init__()n_head_channels = int(q_size / 8)q_size = (q_size, q_size)self.dwc_pe = dwc_peself.n_head_channels = n_head_channelsself.scale = self.n_head_channels ** -0.5self.n_heads = n_headsself.q_h, self.q_w = q_size# self.kv_h, self.kv_w = kv_sizeself.kv_h, self.kv_w = self.q_h // stride, self.q_w // strideself.nc = n_head_channels * n_headsself.n_groups = n_groupsself.n_group_channels = self.nc // self.n_groupsself.n_group_heads = self.n_heads // self.n_groupsself.use_pe = use_peself.fixed_pe = fixed_peself.no_off = no_offself.offset_range_factor = offset_range_factorself.ksize = ksizeself.log_cpb = log_cpbself.stride = stridekk = self.ksizepad_size = kk // 2 if kk != stride else 0self.conv_offset = nn.Sequential(nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, pad_size, groups=self.n_group_channels),LayerNormProxy(self.n_group_channels),nn.GELU(),nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False))if self.no_off:for m in self.conv_offset.parameters():m.requires_grad_(False)self.proj_q = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_k = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_v = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_out = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_drop = nn.Dropout(proj_drop, inplace=True)self.attn_drop = nn.Dropout(attn_drop, inplace=True)if self.use_pe and not self.no_off:if self.dwc_pe:self.rpe_table = nn.Conv2d(self.nc, self.nc, kernel_size=3, stride=1, padding=1, groups=self.nc)elif self.fixed_pe:self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w))trunc_normal_(self.rpe_table, std=0.01)elif self.log_cpb:# Borrowed from Swin-V2self.rpe_table = nn.Sequential(nn.Linear(2, 32, bias=True),nn.ReLU(inplace=True),nn.Linear(32, self.n_group_heads, bias=False))else:self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.q_h * 2 - 1, self.q_w * 2 - 1))trunc_normal_(self.rpe_table, std=0.01)else:self.rpe_table = None@torch.no_grad()def _get_ref_points(self, H_key, W_key, B, dtype, device):ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device),indexing='ij')ref = torch.stack((ref_y, ref_x), -1)ref[..., 1].div_(W_key - 1.0).mul_(2.0).sub_(1.0)ref[..., 0].div_(H_key - 1.0).mul_(2.0).sub_(1.0)ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2return ref@torch.no_grad()def _get_q_grid(self, H, W, B, dtype, device):ref_y, ref_x = torch.meshgrid(torch.arange(0, H, dtype=dtype, device=device),torch.arange(0, W, dtype=dtype, device=device),indexing='ij')ref = torch.stack((ref_y, ref_x), -1)ref[..., 1].div_(W - 1.0).mul_(2.0).sub_(1.0)ref[..., 0].div_(H - 1.0).mul_(2.0).sub_(1.0)ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2return refdef forward(self, x):x = xB, C, H, W = x.size()dtype, device = x.dtype, x.deviceq = self.proj_q(x)q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)offset = self.conv_offset(q_off).contiguous() # B * g 2 Hg WgHk, Wk = offset.size(2), offset.size(3)n_sample = Hk * Wkif self.offset_range_factor >= 0 and not self.no_off:offset_range = torch.tensor([1.0 / (Hk - 1.0), 1.0 / (Wk - 1.0)], device=device).reshape(1, 2, 1, 1)offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)offset = einops.rearrange(offset, 'b p h w -> b h w p')reference = self._get_ref_points(Hk, Wk, B, dtype, device)if self.no_off:offset = offset.fill_(0.0)if self.offset_range_factor >= 0:pos = offset + referenceelse:pos = (offset + reference).clamp(-1., +1.)if self.no_off:x_sampled = F.avg_pool2d(x, kernel_size=self.stride, stride=self.stride)assert x_sampled.size(2) == Hk and x_sampled.size(3) == Wk, f"Size is {x_sampled.size()}"else:x_sampled = F.grid_sample(input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),grid=pos[..., (1, 0)], # y, x -> x, ymode='bilinear', align_corners=True) # B * g, Cg, Hg, Wgx_sampled = x_sampled.reshape(B, C, 1, n_sample)# self.proj_k.weight = torch.nn.Parameter(self.proj_k.weight.float())# self.proj_k.bias = torch.nn.Parameter(self.proj_k.bias.float())# self.proj_v.weight = torch.nn.Parameter(self.proj_v.weight.float())# self.proj_v.bias = torch.nn.Parameter(self.proj_v.bias.float())# 检查权重的数据类型q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Nsattn = attn.mul(self.scale)if self.use_pe and (not self.no_off):if self.dwc_pe:residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels,H * W)elif self.fixed_pe:rpe_table = self.rpe_tableattn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)attn = attn + attn_bias.reshape(B * self.n_heads, H * W, n_sample)elif self.log_cpb:q_grid = self._get_q_grid(H, W, B, dtype, device)displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups,n_sample,2).unsqueeze(1)).mul(4.0) # d_y, d_x [-8, +8]displacement = torch.sign(displacement) * torch.log2(torch.abs(displacement) + 1.0) / np.log2(8.0)attn_bias = self.rpe_table(displacement) # B * g, H * W, n_sample, h_gattn = attn + einops.rearrange(attn_bias, 'b m n h -> (b h) m n', h=self.n_group_heads)else:rpe_table = self.rpe_tablerpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)q_grid = self._get_q_grid(H, W, B, dtype, device)displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups,n_sample,2).unsqueeze(1)).mul(0.5)attn_bias = F.grid_sample(input=einops.rearrange(rpe_bias, 'b (g c) h w -> (b g) c h w', c=self.n_group_heads,g=self.n_groups),grid=displacement[..., (1, 0)],mode='bilinear', align_corners=True) # B * g, h_g, HW, Nsattn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)attn = attn + attn_biasattn = F.softmax(attn, dim=2)attn = self.attn_drop(attn)out = torch.einsum('b m n, b c n -> b c m', attn, v)if self.use_pe and self.dwc_pe:out = out + residual_lepeout = out.reshape(B, C, H, W)y = self.proj_drop(self.proj_out(out))h, w = pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)return y
3. 在train下修改模型
需要在训练的文件里把 model 那里改为对应的 yaml 文件。